- Email: nkoufos@cs.uoi.gr
- Website: http://cs.uoi.gr/~nkoufos

Online social networks often show relationships with complex structures, such as close friends, political and sports rivals. As a result, each person is differently influenced by their friends and enemies. With this in mind, our goal for this project is to extract a signed network from a discussion forum (Reddit) based on the pair-wise interactions of the users, and examine whether or not the stability properties hold. Moreover, we try to predict the sign of the edges based on different techniques on Reddit as well as on Epinions, Slashdot and Wikipedia. We also examine on what degree our datasets generalize between them. The models for the three online social networks provided some interesting information on edge sign prediction, but for Reddit's dataset the results were inconclusive due to the lack of ground truth and poor structural balance.
People's relationships on the web can be characterized as positive or negative. Positive links can either indicate support, approval or friendship, while negative ones can signify disapproval, distrust or disagreement on opinions. Although both positive and negative links have a significant role in many social networks, an overwhelming majority of network researches has considered only positive relationships. Some researchers recently started to focus on investigating negative as well as positive relationships [2], unraveling many interesting properties and principles.
Our main goal will be to extract a signed network from a online discussion forum (Reddit), using the comment interaction of the users. Specifically, we will characterize the relationship between two users, based on the sentiment analysis score of their exchanged comments. This problem is interesting as well as challenging, due to the fact that we do not have any kind of information regarding the actual relationship between users. This is because Reddit, does not allow users to mark other users as their friend or foe.
As our secondary goals, we will extend the learning methods used in [3] for the Epinions, Slashdot, Wikipedia and Reddit dataset and examine their structural balance among with their generalization ability. The problem that we will examine is that for a given link in a social network, we will define its sign to be either positive or negative, depending on some features from the network. The main idea is that we will extract some features based on the degrees of the users as well as from some social psychology theories. We will add some new features to the already existing ones and evaluate their performance. Degree features will be applied to all four datasets, but comment based features such as comment score, will be applied to Reddit dataset only, because of its structure.
The results we obtained regarding the sentiment analysis on the Reddit's dataset, was not satisfying. The structural balance percentage, which is the ratio of triangles that satisfy the balance theory to total triangles, for Reddit was about 50%. To clarify the meaning of this percentage, a random sign assignment on the edges will yield the same percentage.
Considering the edge prediction problem Epinions, Slashdot and Wikipedia datasets, showed a slight increase from the previous methods, but not significant enough. On Reddit's dataset, the classifier accuracy reached a 70% accuracy which is promising but not as good as the results from the other three networks. Comment based features, had no impact at all on the classifiers for Reddit's dataset.
Finally, as it was expected, Reddit dataset does not generalize across the other three datasets well enough. This is probably because of the different nature of the networks.
We used datasets from a widely active discussion forum named Reddit, among with the three large online social networks, Epinions, Slashdot, Wikipedia.
Epinions is a product review Web site, where users are able to characterize other users with "trust" or "distrust". Data spans from 1999 until 2003 and contains 131828 nodes and 841372 edges, where 85% of them are positive.
Slashdot is a technology-related news website, where users can tag other users either as "friends" or as "enemies". This dataset is originated in 2009 and contains 81867 users and 545671 edges of which 78% are positive.
Wikipedia is a collectively authored encyclopedia where users can positively or negatively vote other users to determine their promotion to admins. The data are from 2008 and result in a network of 7118 users and 103747 total votes, with 79% of them being positive.
Reddit is an online discussion forum, where users can comment on other users submissions. As opposed to the previous datasets, Reddit does not provide the ability of marking a user with any kind of positive or negative indication. To extract the relationship between users, we used a sentiment analysis technique, which will be explained in section 3. The data we gathered, separate each topic's submission into two possible categories, either Top scored or highly Controversial. For each category, we used 10 different topics and used various combinations to extract structurally different graphs.
| All | Top | Controversial | |
|---|---|---|---|
| Nodes | 13749 | 9842 | 1745 |
| Edges | 60519 | 38900 | 6136 |
| Epinions | Slashdot | Wikipedia | ||
|---|---|---|---|---|
| + Edges | 85% | 44% | 78% | 79% |
| - Edges | 15% | 56% | 22% | 21% |
In this chapter, we will consider the problem of extracting signed networks from Reddit's dataset, as well as predicting edge sign from all four previously mentioned datasets.
For the three large online social networks, the information needed for creating the graphs is provided. So in this subsection we will focus on the method we used for generating the graph from Reddit's data.
Each topic, may contains several submissions. Each submission is considered as the root, while the replies are separated in depth levels. More specifically, every reply to the initial submission is considered at depth 0, while replies to a specific comment, are considered to be one depth below the comment's depth.
We considered a directed graph, where each user that commented on the topic is a node, and edges are assigned from u → v if user u replied directly to user's v comment (one depth above).
In our dataset, the ground truth is not available, so we decided to use a sentiment analysis technique to extract the sign of each edge, which we will consider as ground truth from now on. More specifically, the relationship between two users is characterized either positive or negative, based on the average sentiment score. The average sentiment score, is calculated based on the exchanged comment list from u to v.
After we created the signed graph based on the methodology explained in section 3.1, we will now consider the edge sign prediction problem. For that problem, we will extend the already existing methodology from [3].
Given a directed graph G = (V, E) with a sign (positive or negative) on each edge, we denote the sign of the edge u → v as 1 when the sentiment score is positive and -1 when the score is negative. In some extremely rare cases where the score is 0, we randomly assign the edge's sign to either of the two categories.
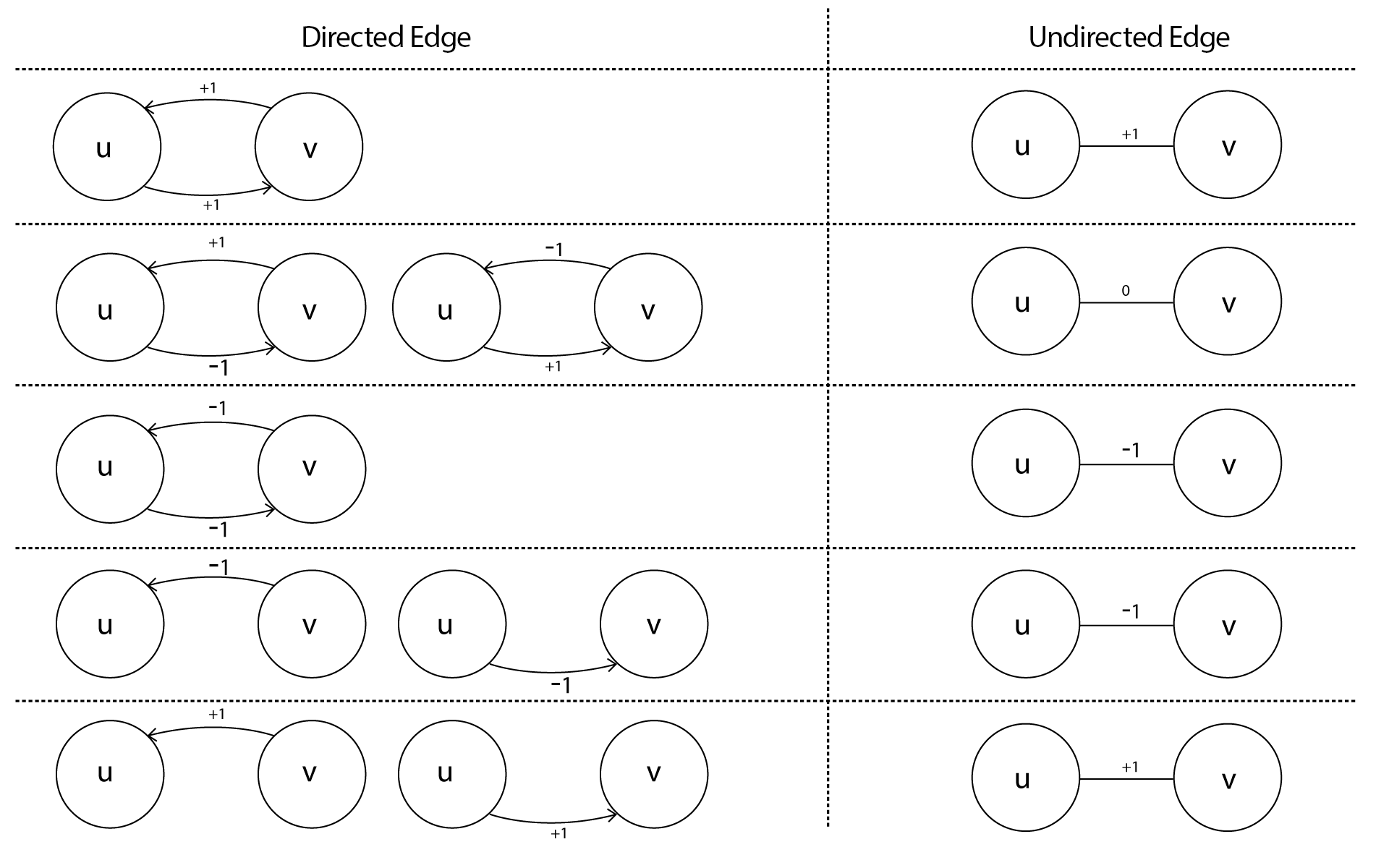
Sometimes we will also be interested in the sign of a directed edge u → v regardless of its direction, as in structural balance. To construct an undirected edge from u to v we used the described steps from Figure 1.
For our edge sign problem, we will suppose that for a particular edge u → v, the sign is hidden and that we are trying to predict it.
For our classifier model, we used an existing implementation of logistic regression to combine all features into an edge sign prediction.
We will separate our dataset evaluation into two main categories. The first one will involve the large online social networks (Epinions, Slashdot, Wikipedia) with features based on degrees and balance and status theory (triads). The second one will involve the Reddit's data with the same features as above, but with an extra addition of some key features based on the comments information.
Degrees. We define the first class of features, as follows. We are interested in predicting the sign of the edge from u to v, so we consider outgoing edges from u and incoming edges to v. Specifically we use the 7 degree features from [3] as well as 4 additional features as described below.
For nodes u and v, we used four degrees features for each one of them.
We also collected three more features.
Triads. For the second class of features, we consider all possible triads involving the edge u → v, consisting of a node w such that w has an edge either to or from u and also an edge either to or from v. There are 16 possible combinations given that we use a signed directed graph. Each edge can lead to 4 possible scenarios due to two directions and two signs. So for a pair of edges, the total combinations are 16 = 4*4.
Comment Based. Due to Reddit's comment information, we were able to extract some features based on comment attributes. We used the total score of each comment, which is measured by the number of up-votes. We also considered each comment's length measured by characters.
In this section, we will describe the experimental methods we used to generate the signed graphs and will also present the various accuracy classification results.
We will firstly address the method we used to calculate the sign of each edge. As we previously mentioned, we used a simple Vader sentiment analysis technique to extract the edge sign. Vader is a Python package, which contains a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media. The method we used, provided us with four different scores:
It is easy to understand that the closer to zero the compound value is, the more erroneous the decision might be. To lower this error percentage, we defined a threshold ε. Comments with compound values between [-ε,ε] are characterized by their negative or positive score.
The next step was to examine our graphs density and connectivity. We created different variations of graphs, combining topics from both Top scored and highly Controversial. For our experiments, we kept three different graphs. The first one was the combination of all topics in both categories. The next two, were a combination of all topics in Top scored and highly Controversial respectively. We noticed that all three graphs were disconnected, not dense enough and follow some kind of power-law like distribution with noise at the tail, as shown in Figure 2.
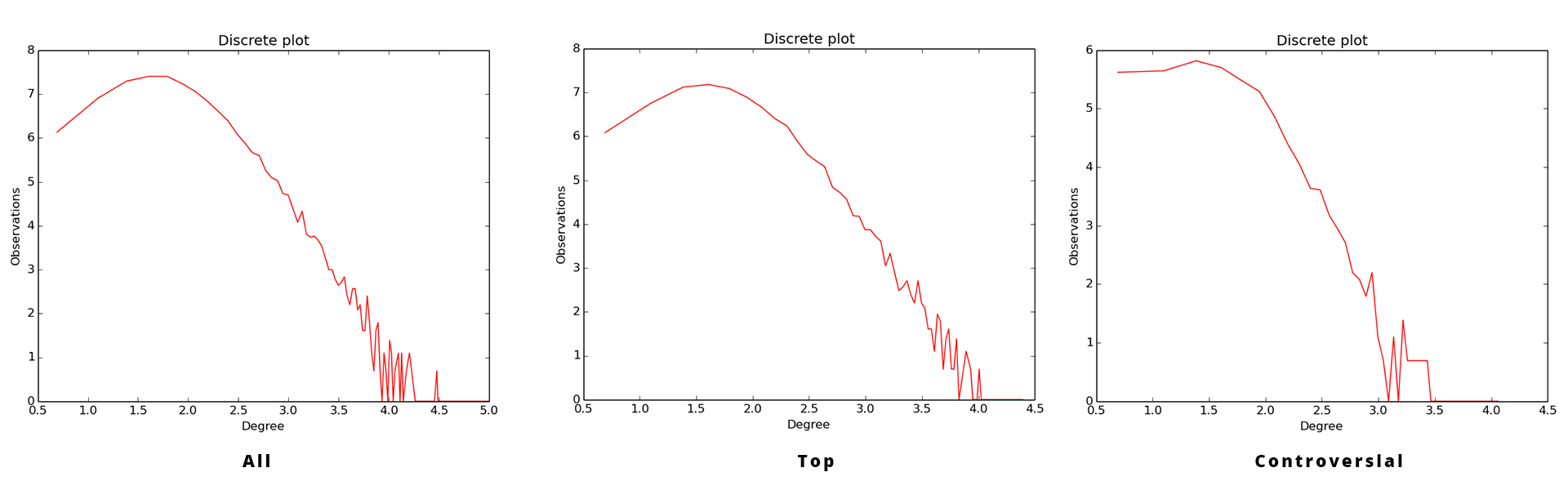
Our first step to solve these problems, was to prune some nodes. We deleted all nodes with total degree below 10. Next, to eliminate the disconnection problem, we extracted the largest connected component from the pruned graph. This resulted in a denser connected graph. In all our experiments, we considered the extracted graphs from the previously mentioned technique.
We will present the results from our classifiers, as well as the structural balance and the generalization across datasets percentage.
Classifiers. We used an already existing Python implementation of logistic regression. We trained our classifier with a random 80 percent of our data, and test it with the rest 20 percent.
We combined the three different classes of features, explained in section 3. Combinations of Degree and Triads class, were used in all four datasets but for the Reddit's dataset we also used the comment based class of features. The combinations used for a directed edge from u to v are:
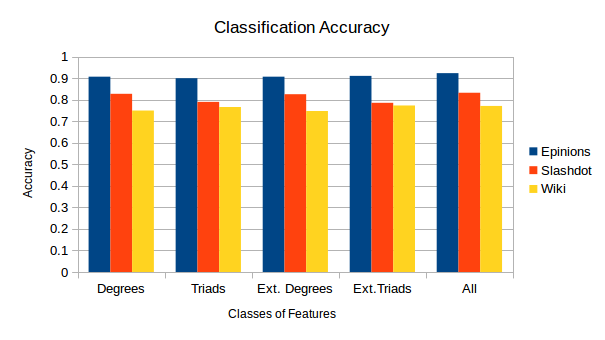
Figure 3 shows that Epinions dataset has a slight accuracy increase on the extended class of features. On the other hand, Slashdot shows a slight decrease on the extended class of features. Finally, in Wikipedia the extended Triads class is the most promising.
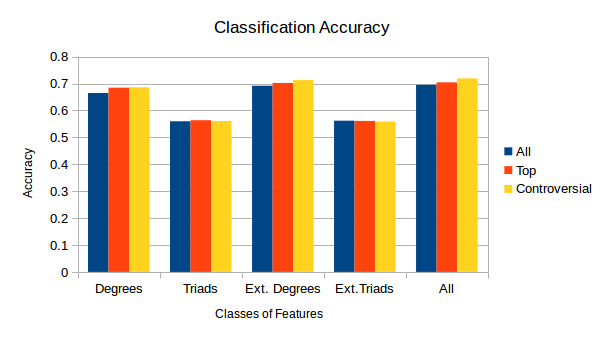
Figure 4 shows that all Reddit's graphs have a worth mentioned accuracy increase from degrees to extended degrees. On the other hand, triads in general perform poorly due to the low structural balance percentage of our graph that we will discuss below.
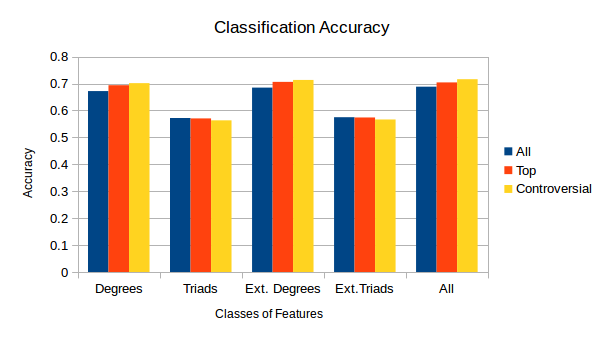
Figure 5 shows that the class of features based on the comments' attributes has no significant impact on the accuracy, because it shows almost the same results as in Figure 4.
Structural Balance. To fully understand the relationship of the classification accuracy to balance theory, it helps to look at the structural balance theory. Social psychologist, Fritz Heider[1], shows the balance on the relationship is based on the common principle that "my friend's friend is my friend", "my friend's enemy is my enemy", "my enemy's friend is my enemy" and "my enemy's enemy is my friend". We measured the structural balance percentage with the following formula: Balance_Percentage =#Triangles_that_satisfy_balance⁄Total_triangles
| Epinions | Slashdot | Wikipedia | ||
|---|---|---|---|---|
| Balance | 90% | 50% | 84% | 83% |
For the three datasets (Epinions, Slashdot, Wikipedia), the structural balance is above 83% and sometimes is near 90%. On the contrary, Reddit's structural balance is nearly 50% which is as good as a random sign assignment on every edge. This problem can be mirrored on the disappointingly low classifier percent on classes involving triads. The results are presented in Table 2.
Generalization Across Datasets. To answer how well the learned predictors generalize across datasets, we examined the following scenarios. We trained each dataset and evaluate it on the other three datasets. In the experiments, we used the All features class due to its better accuracy performance.
As Table 3 shows, Reddit's dataset does not generalize as well as the other three datasets. This inability of generalization is probably due to two different factors. The first one is the different nature of the datasets, in a sense that Reddit is a discussion forum and the other three are social networks. The other one, is the low percent of Reddit's predictors
| Epinions | Slashdot | Wikipedia | ||
|---|---|---|---|---|
| Epinions | 92% | 82% | 76% | 43% |
| Slashdot | 93% | 83% | 77% | 44% |
| Wikipedia | 93% | 84% | 77% | 44% |
| 81% | 75% | 69% | 70% |
We have investigated some mechanisms that determine the signs of links in large social networks and discussion forums, where interactions can be both positive and negative. Our extended methods for sign prediction yield performance that insignificantly improves on previous approaches. More specifically, for the three large online social networks datasets, the extended class of features has an insignificant increase compared to the standard classes.
On Reddit's dataset, the classifiers based on degree features had an average of 68% which is almost 20% above from any random guess in a sense of absolute increase, but it is also almost 15% below the average accuracy of the predictors on the social networks. We believe that the low nature of this percentage, is due to the fact that we lack the ground truth. Regarding the triad feature classes, we can reflect their low percentage to the fact that the structural balance percentage, as mentioned before, is nearly at 50%.
An interesting future work, will be the examination of discussion forum with provided ground truth for users' relationships and a wider variation of features based on the comments, such as down votes.